第32届ACM国际多媒体大会(Proceedings of the 32nd ACM International Conference on Multimedia,ACM MM 2024)将于2024年10月28日至11月1日在澳大利亚墨尔本举行,是中国计算机学会CCF推荐的A类国际会议。厦门大学多媒体可信感知与高效计算教育部重点实验室二十篇论文被录用, 录用论文简要介绍如下:
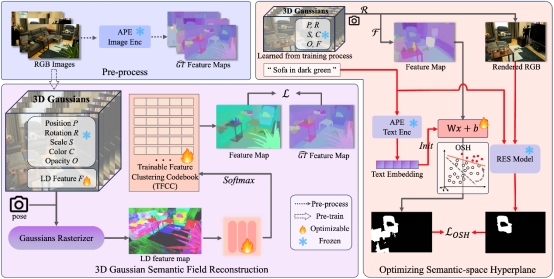
1. GOI: Find 3D Gaussians of Interest with an Optimizable Open-vocabulary Semantic-space Hyperplane
本文提出了一种新型基于三维高斯泼溅 (3D Gaussian Splatting, 3DGS)的开放词汇感知框架GOI,针对开放词汇的文本提示输入实现高精度的三维目标区域定位。为此本文提出了一种有效的语义空间压缩方法,利用场景先验将有噪声的高维语义特征压缩成紧凑的低维向量,嵌入到3DGS中。在开放词汇查询的过程中,现有方法依赖于手动设置的固定经验阈值,根据场景的语义特征和查询文本的语义特征距离来选择区域,这种方法缺乏鲁棒性。因此,本方法将特征筛选的步骤视为特征空间内的超平面划分的过程,仅保留与查询高度相关的场景语义特征。本方法利用现有的2D指向性分割模型来微调语义空间超平面,从而大大提高了三维开放词汇查询的准确性。在多个数据集上的实验证明本方法都超过了之前的最先进的方案,达到了SOTA性能。
本文共同第一作者是信息学院2023级博士研究生曲延松和2024级硕士研究生代绍辉,通讯作者是曹刘娟教授,由2023级博士生李新阳、2023级博士生林将航、张声传助理教授、纪荣嵘教授共同合作完成。
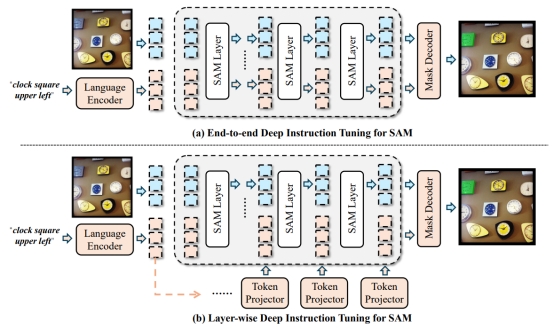
2. Deep Instruction Tuning for Segment Anything Model
Segment Anything Model(SAM)已成为多媒体和计算机视觉领域的研究热点,它在各种(非)条件图像分割任务中表现出强大而通用的能力。尽管 SAM 可以支持不同类型的分割提示,但与基于点和框引导分割相比,它在文本指示任务上的表现要差得多。针对这个问题,本文提出了两种简单而有效的SAM深度指令调优(DIT)方法,一种是end-to-end的,另一种是layer-wise的。本文认为深度文本指令调优是缓解其默认轻量级掩模解码器中浅层融合方案引起的这种缺陷的关键。在几乎不改变SAM主体结构下,DIT 就可以直接将 SAM 的图像编码器转换为独立的视觉语言学习器,而不是构建额外的深度融合分支,从而最大限度地发挥其卓越的分割能力。在三个极具竞争力的RIS基准数据集上的广泛实验表明,简单的end-to-end DIT可以大幅提高SAM性能,而layer-wise DIT可以进一步将性能提高到最先进的水平。
该论文第一作者是人工智能研究院2022级硕士生黄霄瑞,通讯作者是周奕毅副教授,由信息学院2021级博士生罗根、2020级硕士生朱朝阳、2023级硕士生佟浡、孙晓帅教授、纪荣嵘教授共同合作完成。
3. Advancing Multimodal Large Language Models with Quantization-Aware Scale Learning for Efficient Adaptation
本文首次研究了参数量化在多模态大语言模型中缓解视觉-语言指令调优时遇到的显著资源限制的潜力,提出了一种基于多模态预热的量化感知尺度学习方法 (QSLAW)。该方法基于两个关键创新:(1) 以学习LLM权重的分组尺度因子作为高效微调方式,以减轻由激活异常值引起的量化误差,并实现更有效的视觉-语言指令调优;(2) 实现一种多模态预热,逐步整合语言和多模态训练样本,从而防止量化模型对多模态数据的过拟合,同时确保多模态大语言模型对下游视觉-语言任务的稳定适应。大量实验表明,由QSLAW量化的模型在性能上与其全精度对应模型相当,甚至超越,同时在VL调优时间和GPU消耗方面最多可减少1.4倍。

该论文第一作者是信息学院2023级硕士生谢晶晶,通讯作者是曹刘娟教授,由2021级博士生张玉鑫、林明宝(新加坡Skywork AI 2050研究院)、纪荣嵘教授共同合作完成。
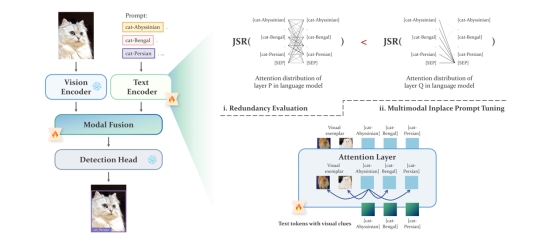
4. Multimodal Inplace Prompt Tuning for Open-set Object Detection
将大型语言模型集成到开放世界检测框架中,能显著提高检测器在新环境中的适应性。通过大语言模型生成的提示文本表征,有助于在开放世界检测器中为图像类别构建分类边界。然而,直接在检测系统中微调语言模型会导致冗余的注意力模式,从而产生次优的文本表征。为了充分利用大型语言模型的能力并增强其针对检测任务的编码表征,本研究引入了一种冗余评估指标,以识别冗余的注意力模式。在冗余度较高的区域,本文引入了多模态同步提示调优(MIPT),利用更具体的视觉信息丰富文本提示。实验结果验证了本文MIPT框架的有效性,在多个基准测试中取得了显著提升,例如将GLIP-L在ODinW-35上的表现从22.6%提升到25.0%,并在LVIS上取得了9.0%的性能提高。
该论文第一作者是信息学院2022级硕士生李桂林,通讯作者是纪荣嵘教授,由张梦丹(腾讯优图实验室)、郑侠武副教授等共同合作完成。
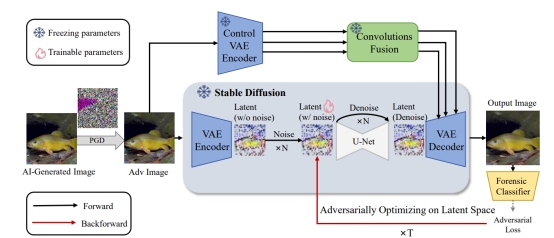
5. StealthDiffusion: Towards Evading Diffusion Forensic Detection through Diffusion Model
生成模型的快速进展引发了AI生成内容隐蔽(AIGC-S)这一关键任务,其目标是创建能够规避法医检测器和人工检查的AI生成图像。对这一任务展开研究对于理解现有检测方法的漏洞和开发更强大的生成技术至关重要。当前的基于对抗攻击的方法通常会引入可见噪声,具有较差的可迁移性,并且未能解决AI生成图像与真实图像之间的光谱差异。针对上述挑战,本文提出了一种基于StableDiffusion的框架StealthDiffusion,能够将AI生成的图像修改为高质量的、不易察觉的对抗性样本,从而避开最先进的法医检测器。StealthDiffusion包括两个主要组件:潜在对抗优化以及控制变分自编码器(Control-VAE),前者在稳定扩散的潜在空间中生成对抗性扰动,后者在不影响原始扩散模型生成过程的情况下,进一步减少生成的对抗性图像与真实图像之间的光谱差异。实验表明,StealthDiffusion在白盒和黑盒环境下均表现出较好的性能,能够有效地将AI生成的图像转化为频谱与真实图像相似的高质量对抗性伪造样本。这些由StealthDiffusion处理后的图像被最先进的法医分类器分类为真实图像,并且难以被人类辨别。
该论文共同第一作者是人工智能研究院2023级硕士生周子寅和2021级博士生孙可,通讯作者是孙晓帅教授,由2022级硕士生陈忠淅、2020级博士生匡华峰、纪荣嵘教授共同合作完成。
6. QueryMatch: A Query-based Contrastive Learning Framework for Weakly Supervised Visual Grounding
视觉定位(VG)是一项根据自然语言描述定位物体的跨模态分析任务。近期的研究致力于探索弱监督学习方法以降低标注的成本。传统弱监督方法通常采用Anchor-Text匹配范式,尽管效率较高,但基于Anchor的表示常常含有噪声且不足以充分描述物体信息,阻碍了视觉与语言模态的精准对齐。针对这一瓶颈,本文提出了QueryMatch,一种新颖的基于Query的单阶段框架,用于弱监督视觉定位。不同于以往的工作,QueryMatch使用一组Query特征来表示候选物体,更易于与目标物体建立精确的一对一关联。QueryMatch将弱监督下的视觉定位重定义为一个Query-Text匹配问题,可以通过基于Query特征的对比学习来进行优化。基于QueryMatch框架,本文进一步提出了负样本质量估计(NSQE)策略,通过主动选择高质量的Query特征来增强对比学习中负样本的语义信息,可极大地促进QueryMatch的弱监督学习效果。在两个视觉定位任务(REC和RES)的三个基准数据集RefCOCO、RefCOCO+和RefCOCOg上的实验结果展示了QueryMatch在弱监督领域的先进性能。在RefCOCO数据集弱监督REC任务上提升了5%,弱监督RES任务上提升了超过20%。
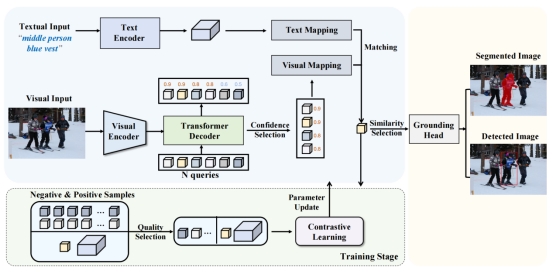
该论文第一作者是信息学院2022级硕士生陈晟新,通讯作者是孙晓帅教授,由罗根博士、周奕毅副教授、江冠南博士(宁德时代)、纪荣嵘教授共同合作完成。
7. Cantor: Inspiring Multimodal Chain-of-Thought of MLLM
现有的多模态思维链方法通常将问题分解为多个相关的子任务,并调用各种外部工具依次处理。然而,由于视觉信息不足和低级感知工具的局限性,这种范式在决策时面临潜在的“决策幻觉”,以及低级感知工具无法提供高级推理信息的挑战。为此,本文提出了一种创新的多模态CoT框架,称为Cantor,其特征是感知决策架构。Cantor首先利用MLLM或LLM扮演决策生成器,通过整合视觉输入来分析图像和问题,确保上下文信息对齐。此外,Cantor利用MLLM的高级认知功能,使其扮演多个不同的专家来获取更高层次的认知信息,增强CoT生成过程。在无需额外训练的情况下,Cantor在两个复杂的视觉推理数据集ScienceQA 和MathVista上显著提高了CoT性能,证明了有效性。
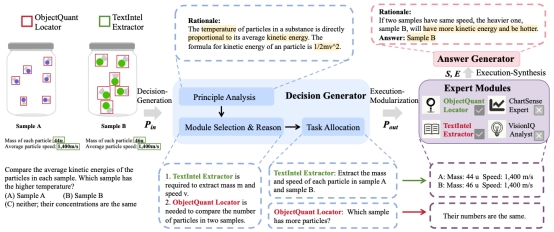
该论文共同第一作者是信息学院2022级硕士生高体民、陈珮娴(腾讯优图实验室)和张梦丹(腾讯优图实验室),通讯作者是曹刘娟教授,由张岩工程师、孙星(腾讯优图实验室)、纪荣嵘教授等共同合作完成。
8.Adaptive Selection based Referring Image Segmentation
指示性图像分割(RIS)旨在根据文本描述分割图像中的特定区域。现有的单阶段方法已探索了各种融合策略,但它们面临两个重要问题。首先,大多数方法依赖于从视觉编码器层手动选择的视觉特征,缺乏根据语言偏好灵活选择视觉特征的能力。其次,将单词级特征直接融合到粗粒度对齐特征中会破坏已建立的视觉-语言对齐,导致性能不佳。为解决这些问题,本文提出了一种创新的RIS框架,称为自适应选择与双对齐(ASDA)框架。该框架通过自适应对齐视觉和语言特征克服上述挑战。ASDA的创新之处体现在两个方面。首先,本文设计了一个自适应特征选择和融合(AFSF)模块,动态选择与不同文本描述相关的视觉特征。AFSF配备了尺度特征聚合器,提供多层次的粗粒度特征,既保留关键的低级细节,又为后续的双对齐提供强大特征。其次,本文引入了单词引导的双分支对齐器(WGDA),通过单词引导的注意力将粗粒度特征与语言提示融合,解决视觉-语言错位问题,确保语言描述直接与掩码预测作用。这使得模型能够专注于相关的图像区域并进行准确预测。广泛的实验结果表明,本文的ASDA框架在RefCOCO、RefCOCO+和G-Ref基准测试中优于现有最先进的方法。这种改进不仅展示了ASDA在捕捉细粒度视觉细节方面的优势,还表明其在处理多样化描述时的鲁棒性和适应性。
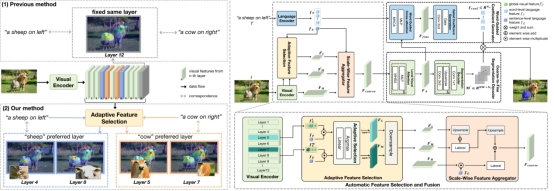
该论文共同第一作者是人工智能研究院2023级硕士生岳鹏飞和2023级博士生林将航,通讯作者是张声传助理教授,由2023级博士生林将航、胡杰(宁德时代)、曹刘娟教授、纪荣嵘教授等共同合作完成。
9. 3D-GRES: Generalized 3D Referring Expression Segmentation
3D指向性分割(3D-RES)旨在根据自然语言描述在三维空间中分割特定实例。然而,当前的方法仅限于分割单个目标,这限制了该任务的多样性。为克服这一限制,本文引入了广义3D指向性分割(3D-GRES),其扩展了根据自然语言指令分割任意数量实例的能力。针对这一更广泛的任务,本文提出了多查询解耦交互网络(MDIN),旨在将多目标分割任务分解为更简单的单个分割任务。MDIN包括两个基本组件:文本驱动稀疏查询(TSQ)和多目标解耦优化(MDO)。TSQ生成分布在关键目标上的稀疏点云特征,作为查询的初始化。同时,MDO负责在多目标场景中将每个目标分配给不同的查询,同时保持其语义一致性。为适应这一新任务,本文构建了一个新数据集Multi3DRes。MDIN在该数据集上显著优于现有模型,为复杂的多目标3D场景理解开辟了新路径。
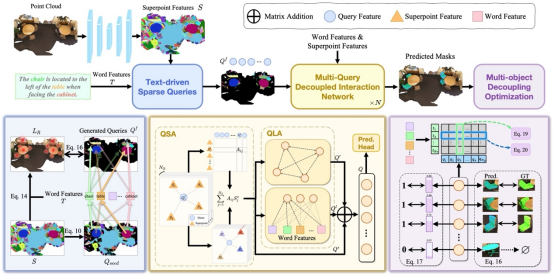
该论文的共同第一作者是信息学院2022级硕士吴昌鲡与2023级硕士刘依航,通讯作者是纪荣嵘教授,由博士后研究员纪家沂、孙晓帅教授等共同合作完成。
10. HmPEAR: A Dataset for Human Pose Estimation and Action Recognition.
三维人体姿态估计作为对身体关节空间位姿的精细估计,是理解人体运动的基础。另一方面,人体动作识别关注人体运动的动态特征,提供了对人的行为和意图的更高级理解。然而,现有的人体姿态估计数据集缺乏动作语义,而人体动作识别数据集则缺乏点云数据或详细的三维人体姿态。针对以上问题,本文首先提出HmPEAR数据集。本数据集包括同步采集的图像、激光雷达点云、三维人体姿态和动作类别数据,涉及10个不同场景和25个人体对象,标注了40种日常人类动作的6千个动作片段,总数据超过30万帧。其中,有25万帧数据包含了经专业的动作捕捉系统捕获并进一步优化的三维人体姿态。基于本数据集,论文进一步提出了基于多模态和多任务融合的人体姿态估计和人体动作识别基准模型,验证了人体姿态估计和动作识别任务间相互增强的潜力,展示了人体姿态估计和动作识别跨任务协同的可能性。论文通过大量实验展示了本数据集对现有方法的挑战性及本文提出的基准模型的可用性。
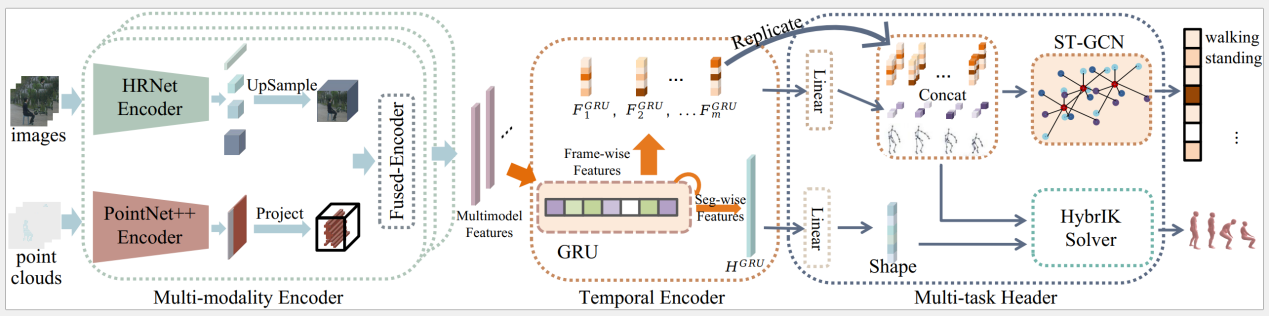
该论文的共同第一作者是信息学院2021级硕士生林逸泰和2023级硕士生魏智杰,通讯作者是温程璐教授,由张万发、林希平、戴雨笛、沈思淇副教授、许岚助理教授(上海科技大学)、王程教授共同合作完成。
11. Semi-Supervised Visible-Infrared Person Re-Identification via Modality Unification and Confidence Guidance
本文提出了一种新颖的模态统一与置信引导(MUCG)的半监督学习框架,致力于解决半监督可见-红外人重识别(SSVI-ReID)任务中两个关键挑战:噪声伪标签和显著的模态差异。本文首先引入了一个动态中间模态生成(DIMG)模块,该模块能够将标记可见光图像的知识迁移到未标记的红外图像上,从而增强伪标签的质量并缩小模态间的差距。同时,本文设计了一种加权身份损失(WIL),利用置信度加权策略降低模型对错误标签的依赖。此外,本文还开发了一种模态一致性损失(MCL),有效缩小了可见光和红外特征的分布距离,进一步促进了模态统一特征的学习。大量实验表明,MUCG在提升SSVI-ReID任务的性能方面具有显著优势,明显超越了现有的半监督方法。
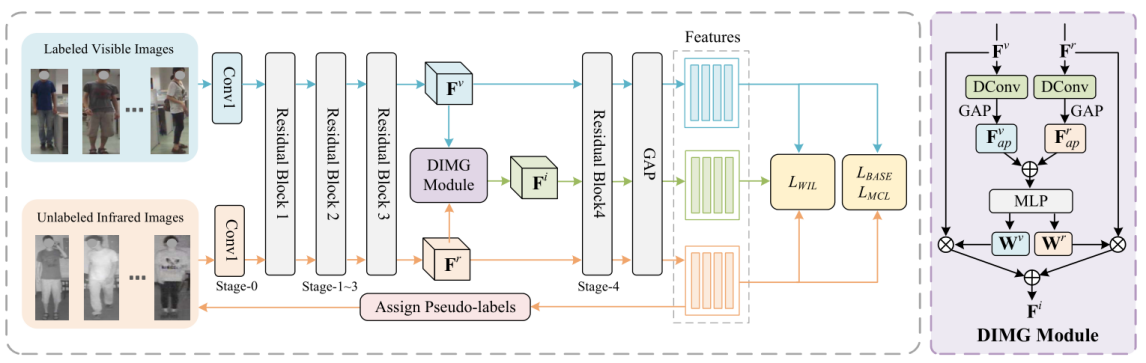
该论文第一作者是信息学院2022级硕士生郑希颖,通讯作者是王菡子教授,由张玉康博士、卢杨助理教授共同合作完成。
12. GLATrack: Global and Local Awareness for Open-Vocabulary Multiple Object Tracking
针对开放词汇多目标跟踪在复杂环境中目标外观表征不明确、语义信息损失等关键问题,本文拟研究基于全局和局部感知的开放词汇多目标跟踪算法(GLATrack)。该方法能通过引入区域感知特征增强模块细化全局知识来补充局部目标信息,增强语义表示并弥合图像特征图与区域特征之间的分布差距;提出了双向语义互补策略,在知识蒸馏过程中动态选择参考帧中的有价值信息,缓解关键帧中目标信息缺失导致的语义错位问题;引入外观丰富度测量模块,为具有不同外观的目标提供适当的表示,提高模型的跟踪性能。
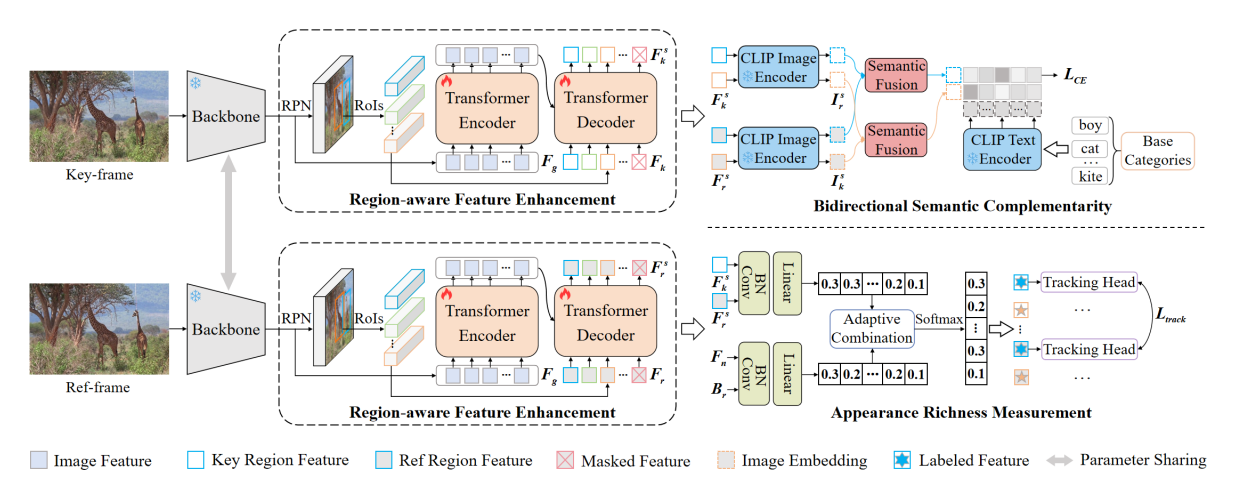
该论文的第一作者是人工智能研究院2023级博士生黎光耀,通讯作者是王菡子教授,由2022级硕士生简亚军、严严教授共同合作完成。
13.Diverse Consensuses Paired with Motion Estimation-Based Multi-Model Fitting
多模型拟合存在大量噪声和异常数据,仅使用单一一致性或隐式融合模型来模拟数据点和模型假设之间的相关性往往会导致不正确的模型拟合。本文提出了一种基于多样一致性配对与运动估计的多模型拟合(CMMF)方法,该方法利用三种不同的一致性以及模型间的协作来提高多模型拟合的有效性。本文设计了一个切线一致性残差重建(TCRR)模块,用于在像素级捕获两点的运动结构信息。此外,本文还引入了交叉一致性亲和度(CCA)框架,以加强数据点和模型假设之间的相关性。为了应对多体运动估计的挑战,本文提出了一种嵌套一致性聚类(NCC)策略,该策略将多模型拟合转化为运动估计问题,它明确地建立了模型之间的运动协作,并确保了多个模型良好拟合。
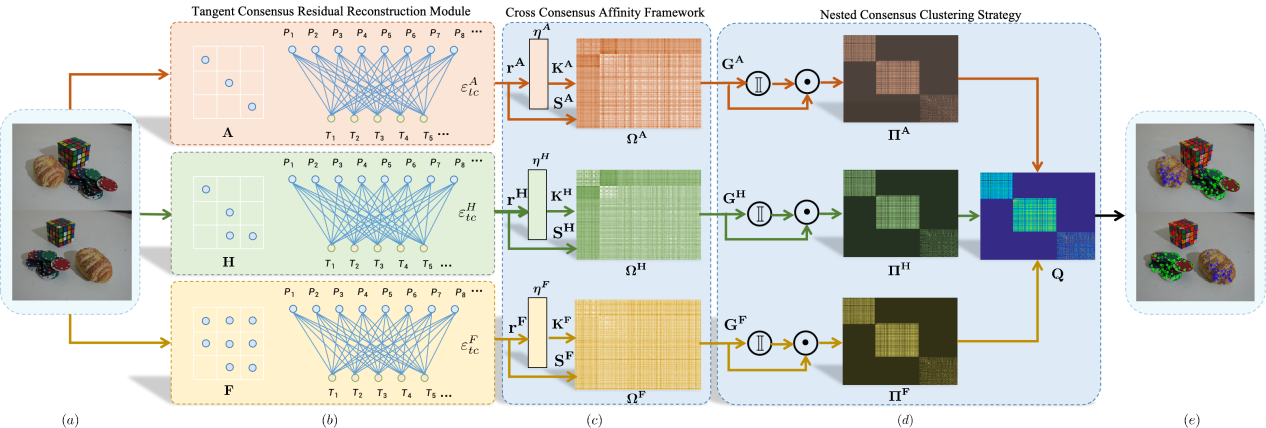
该论文第一作者是信息学院2023级博士生尹文玉,通讯作者是卢杨助理教授,由王菡子教授、林舒源博士(暨南大学)共同合作完成。
14.Robust Pseudo-label Learning with Neighbor Relation for Unsupervised Visible-Infrared Person Re-Identification
无监督可见光-红外行人重识别(uSWI-&eDD)是一项极具挑战的任务,其目的是在没有任何标注的情况下匹配可见光和红外模态下的行人图像。最近,聚类伪标签方法已成为 USVI-ReID 的主要方法,但是不可靠的伪标签严重影响识别精度。为了解决这一问题,本文设计了一种基于邻居关系的鲁棒伪标签学习框架(RPNR)。具体而言,本文首先引入了一个简单而有效的噪声伪标签校准模块来校正噪声伪标签;设计了邻居关系学习模块,通过对所有样本间潜在的相互作用进行建模来降低较高的类内差异;进一步设计了最优传输原型匹配模块,以建立可靠的跨模态对应关系。在此基础上,通过内存混合学习模块,以联合学习特定模态信息和模态不变信息。在两个基准数据集(SYSU-MM01 和RegDB)上进行的综合实验表明,RPNR的性能优于当前最先进的GUR,Rank-1 性能提高了10.3%。
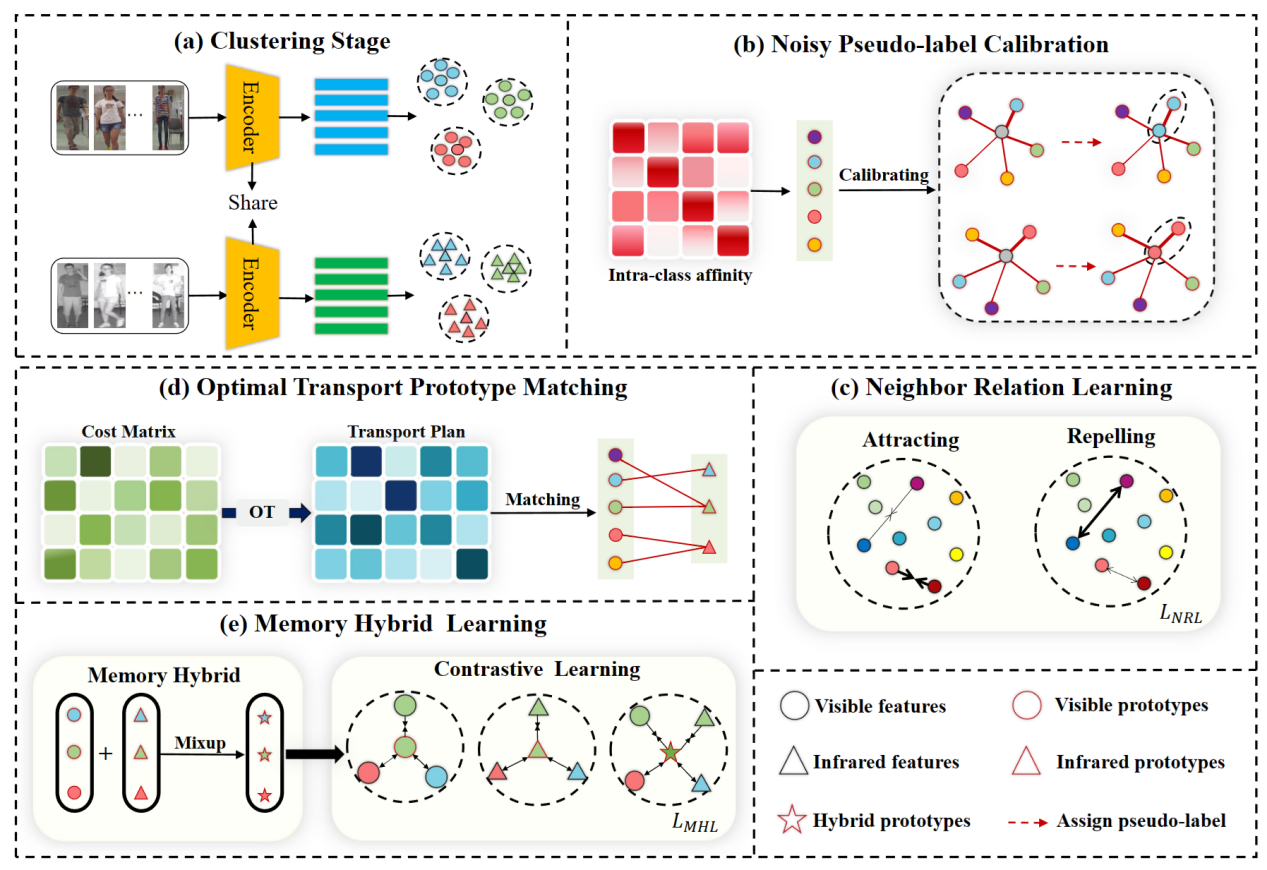
该论文的共同第一作者是信息学院2023级硕士生尹祥博和人工智能研究院2022级博士生施江鸣,通讯作者是其导师曲延云教授和谢源教授(华东师范大学),由张亚超(清华大学深圳研究院)、卢杨助理教授、张志忠(华东师范大学)等共同合作完成。
15. CLIP2UDA: Making Frozen CLIP Reward Unsupervised Domain Adaptation in 3D Semantic Segmentation
本文探索了如何利用多模态信息解决3D语义分割的域自适应问题。现有的方法通常试图通过对齐源数据和目标数据之间的特征来减轻域差异。然而,这种实现在应用于图像感知时存在不足,因为与点云相比,图像对环境变化的敏感性更高。为了解决这一问题,本文提出一种利用图像语言预训练模型(CLIP)的先验知识来提升跨域3D语义分割鲁棒性的框架 (CLIP2UDA)。首先,引入了一个视觉驱动的提示适应模块 (VisPA),通过预训练的视觉编码器生成的2D域特征,学习特定于任务的文本提示。其次,为了学习多模态域不变特征表示,提出了一个文本指导的上下文交互模块 (TexCI),通过跨解码器层进行类感知融合和语义感知融合,得到文本引导的视觉特征,然后将该特征与图像和属性特征融合,并在共享解码器中进行层次性交互,从而产生联合的视觉预测。最后,将3D特征与点级联合特征进行互学习,受益于视觉语言结构相关性,增强了多模态域不变特征的表示能力。该方法在Day/Night、USA/Singapore、vKITTI/sKITTI和A2D2/sKITTI自适应场景中显著优于目前最先进的跨模态UDA方法。
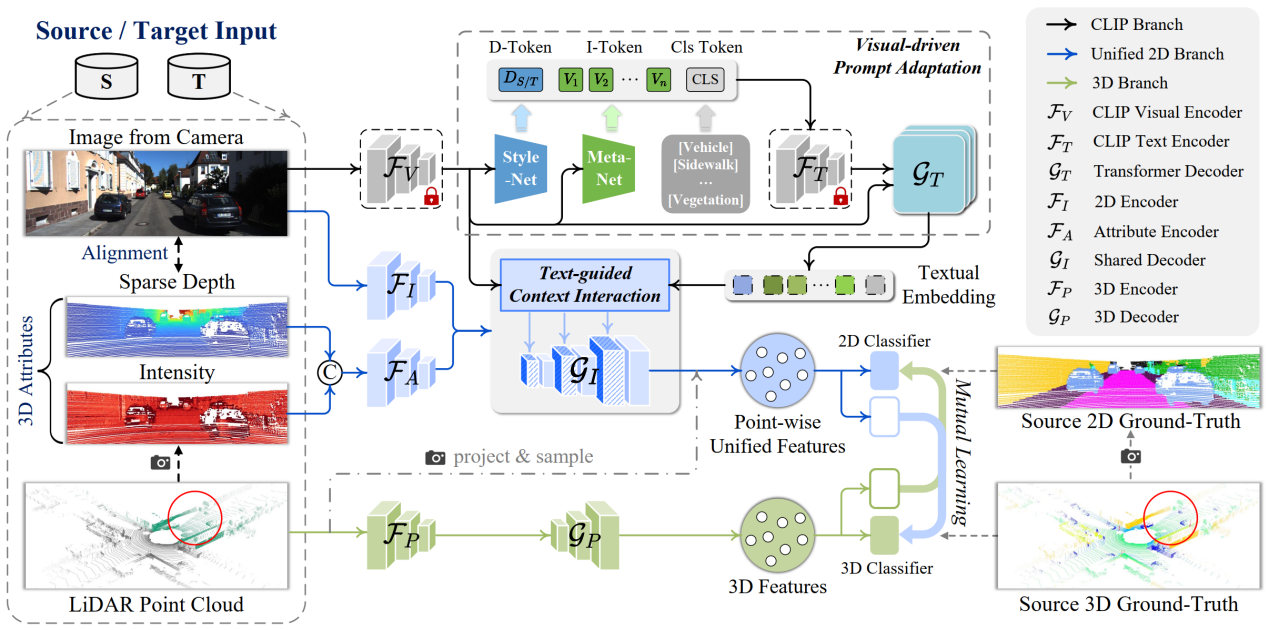
该论文的第一作者是信息学院2021级博士生吴垚,通讯作者是其导师曲延云教授和谢源教授(华东师范大学),由2022级硕士生邢明炜、张亚超(清华大学深圳研究院)等共同合作完成。
16. Efficient Perceiving Local Details via Adaptive Spatial-Frequency Information Integration for Multi-focus Image Fusion
多焦点图像融合(MFIF)旨在将多个具有不同聚焦区域的图像合并成一张全聚焦图像。现有的无监督深度学习方法仅在空间域内融合图像的结构信息,忽略了在频域探索可能的潜在解决方案。本文首次尝试集成空域和频域的图像信息以实现高质量的MFIF。本文提出了一种新颖的无监督空-频双域交互MFIF网络,名为SFIMFN,它由三个关键组件组成:自适应频域信息交互模块(AFIM)、基于Ret-Attention的空间信息提取模块(RASEM)和可逆双域特征融合模块(IDFM)。具体来讲,在AFIM中,通过结合多张图像的幅值和相位信息,交互式地探索全局上下文信息。在RASEM中,通过显式设计具有2D衰减自注意机制的定制Transformer,鼓励网络捕捉重要的局部高频信息。最后,IDFM在信息无损的原则下融合空-频双域信息,生成全聚焦图像。在不同数据集上的大量实验表明,本文方法在定性和定量指标以及泛化能力上均显著优于最新的无监督方法。
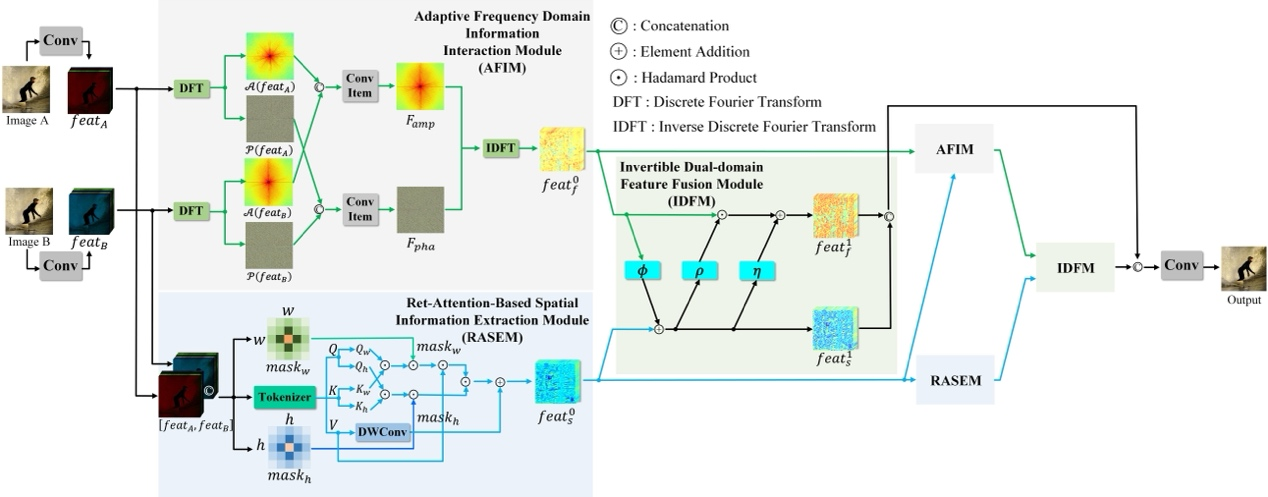
该论文第一作者是信息学院2022级硕士生黄婧嘉,通讯作者是涂晓彤助理教授,由丁兴号教授、黄悦教授等合作完成。
17.P2SAM: Probabilistically Prompted SAMs Are Efficient Segmentator for Ambiguous Medical Images
单输入生成多个合理输出的能力对处理视觉场景中的固有歧义具有深远的影响,这在不同专家为单个医学图像提供不同语义分割注释的场景中尤为明显。现有的方法依赖于概率建模来描述这种模糊性,并依赖大量的多输出注释数据来学习这种概率空间。然而,当只有有限数量的模糊标记数据可用时,这些方法往往会失败,这在现实世界的应用中很常见。为了克服这些挑战,本文提出了一种新的框架,称为P2SAM,该框架在分割模糊对象时利用了分段任意模型(SAM)的先验知识。具体来说,本文深入研究了SAM在确定性分割中的固有缺点,即输出对提示的敏感性,并通过为提示引入先验概率空间,巧妙地将其转化为模糊分割任务的优势。实验结果表明,通过使用少量医生模糊注释的样本,本文的策略显著提高了医学分割的准确性和多样性。针对最先进方法的严格基准测试实验表明,本文的方法在较少的训练数据(仅使用5.5%的样本)下实现了卓越的分割精度和多样化的输出。P2SAM标志着在数据有限的现实世界场景中,概率模型的实际部署迈出了重要的一步。
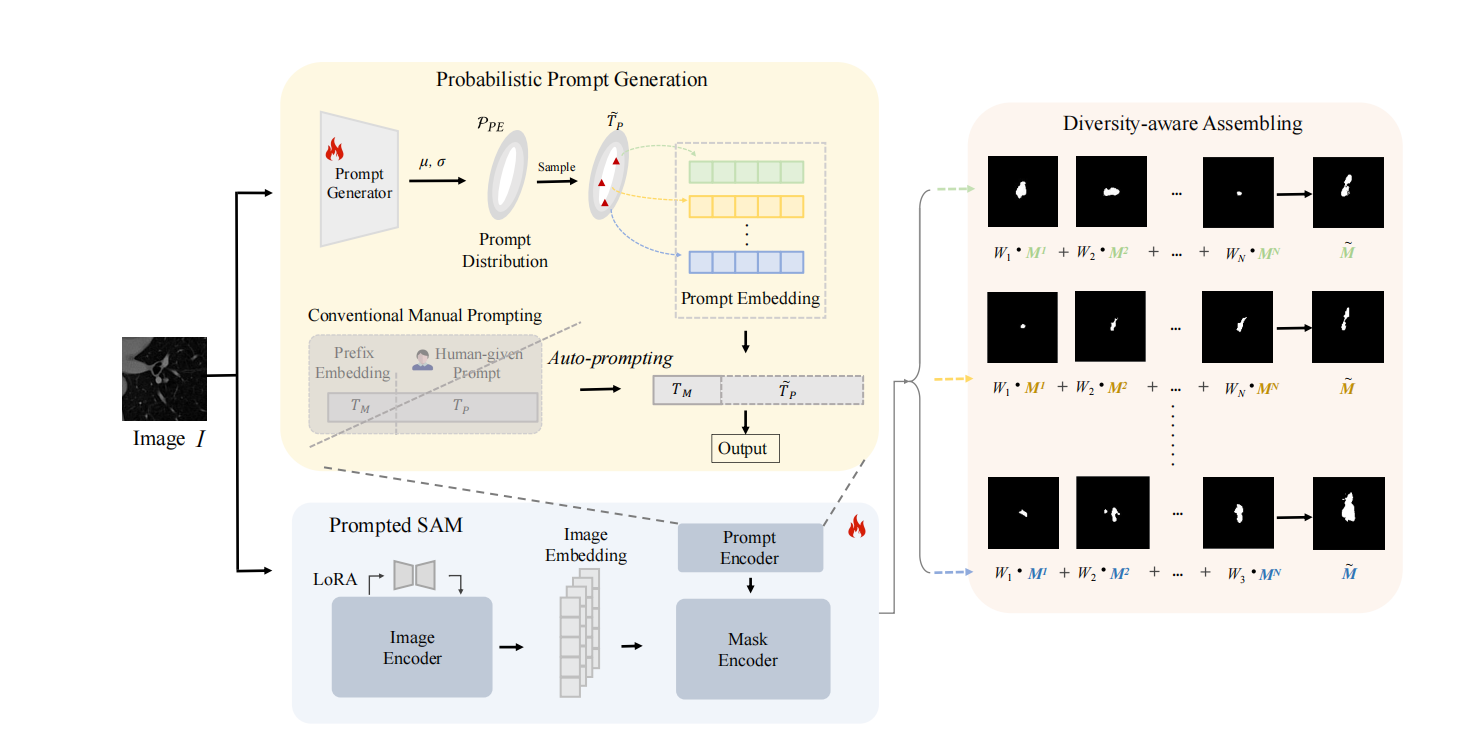
该论文共同第一作者是信息学院2023级硕士生黄誉之和李宸鑫博士(香港中文大学),通讯作者是李宸鑫博士和黄悦教授,由丁兴号教授、涂晓彤助理教授等共同合作完成。
18. SimCLIP: Refining Image-Text Alignment with Simple Prompts for Zero-/Few-shot Anomaly Detection
最近,经过大规模Web数据完成预训练的视觉语言模型,在小零样本异常检测领域内展现出了优越的性能表现。然而,现有方法仍然存在两个问题。第一,文本提示需要通过大量的专家知识来构建。第二,当前的方法使用不对齐的高层语言特征和低层视觉特征来完成异常分割任务。基于此,本文提出了一个名为SimCLIP的方法,旨在通过多层级的视觉适配器(MHVA)和隐式提示学习模块(IPT)之间的双向适应来修正视觉语言特征不对齐的问题。SimCLIP只需简单的二分类文本提示就能高效完成零样本异常检测任务。此外,本文还提出了它的扩展版本SimCLIP+,通过整合视觉嵌入信息和跨模态协同信息来解决小样本场景下的异常检测任务。本文为预训练视觉语言模型高效适配具体的下游小零样本异常检测任务提供了新的视角。
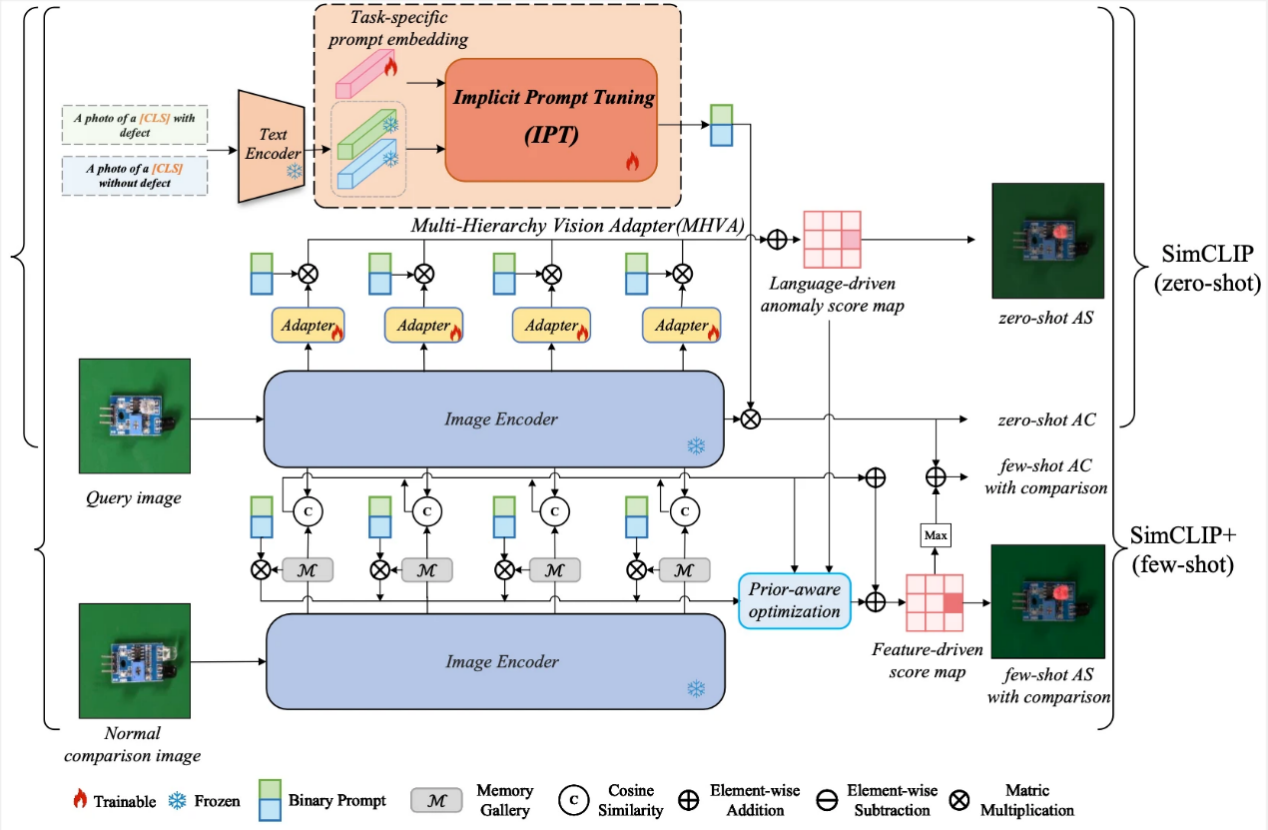
该论文共同第一作者是人工智能研究院2022级硕士生邓成浩和徐浩特博士,通讯作者是涂晓彤助理教授,由丁兴号教授、黄悦教授等共同合作完成。
19. SkipVSR: Adaptive Patch Routing for Video Super-Resolution with Inter-Frame Mask
本文提出了基于自适应跳步的视频超分辨率动态推理方法,以动态网络结构的角度实现模型推理加速。同一视频序列往往针对同一场景,帧间特征具有高度相似性,但所有帧间特征均采用相同深度的模块进行特征融合,这造成了模型结构的冗余。针对这一问题,本文将动态推理技术拓展至视频超分辨率任务,以动态网络结构的角度探索模型加速问题。通过探索序列帧之间的特征相似性,设计自适应掩码生成器来指示模块的执行。为保证模型精度,该方法设计了高维空间特征约束,以减少前序帧所带来的累积误差。在公开数据集上的实验结果表明,该方法能在减少计算资源消耗的同时,仍能保持图像重构纹理。
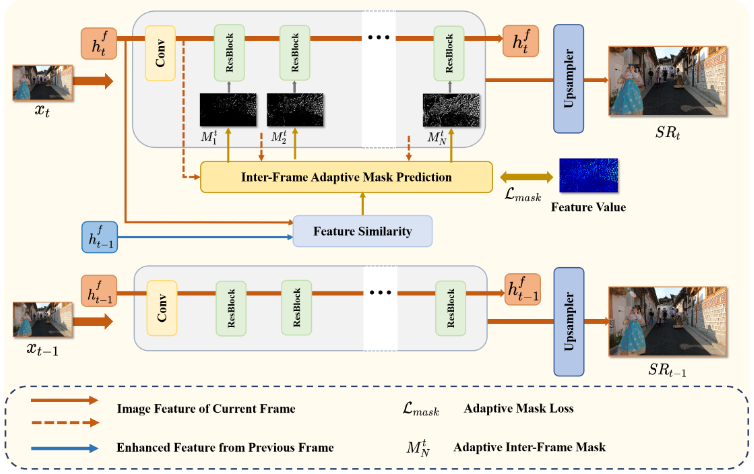
该论文的共同第一作者是信息学院2021级硕士生艾泽坤与2020级博士生罗小同,通讯作者是其导师曲延云教授和谢源教授(华东师范大学)。
20. Prompting to Adapt Foundational Segmentation Models
本文提出了一种创新的“prompting-to-adapt”适应性范式,通过引入图像提示器来增强基础分割模型在不同图像领域的泛化能力。该提示器利用少量样本对生成领域特定提示,并结合多样的图像处理技术提升模型适应性。针对图像提示的非微分性问题,本文设计了基于信息熵的梯度下降优化策略。在多个数据集上的实验显示,该方法有效提升了模型的适应性,并且生成的提示具有较高的可解释性,有助于深入理解图像处理机制。
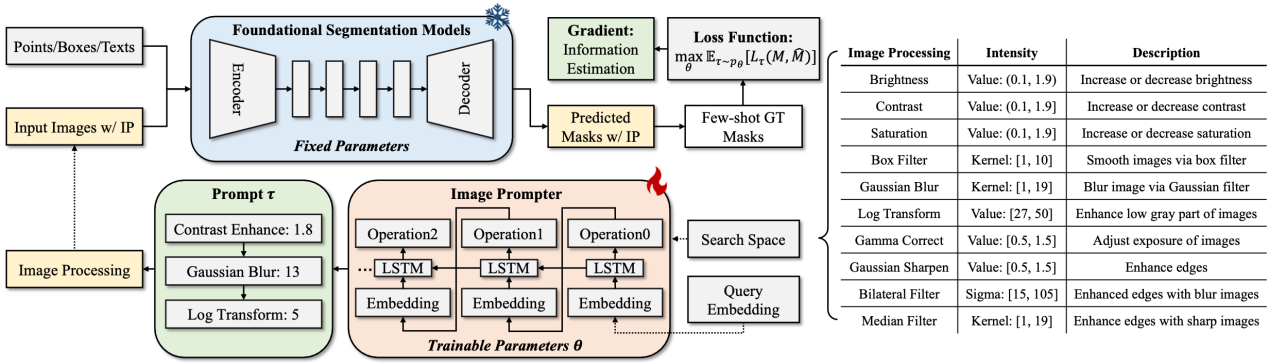
该论文第一作者是胡杰博士(宁德时代),通讯作者是江冠南博士(宁德时代),由信息学院2019级博士生李杰、2022级硕士生马跃、曹刘娟教授、纪荣嵘教授等共同合作完成。
(信息学院)